Iretiayo Akinola*,
Zizhao Wang*,
Junyao Shi,
Xiaomin He,
Pawan Lapborisuth,
Jingxi Xu,
David Watkins-Valls,
Paul Sajda,
and
Peter Allen
Columbia Robotics Lab
Abstract
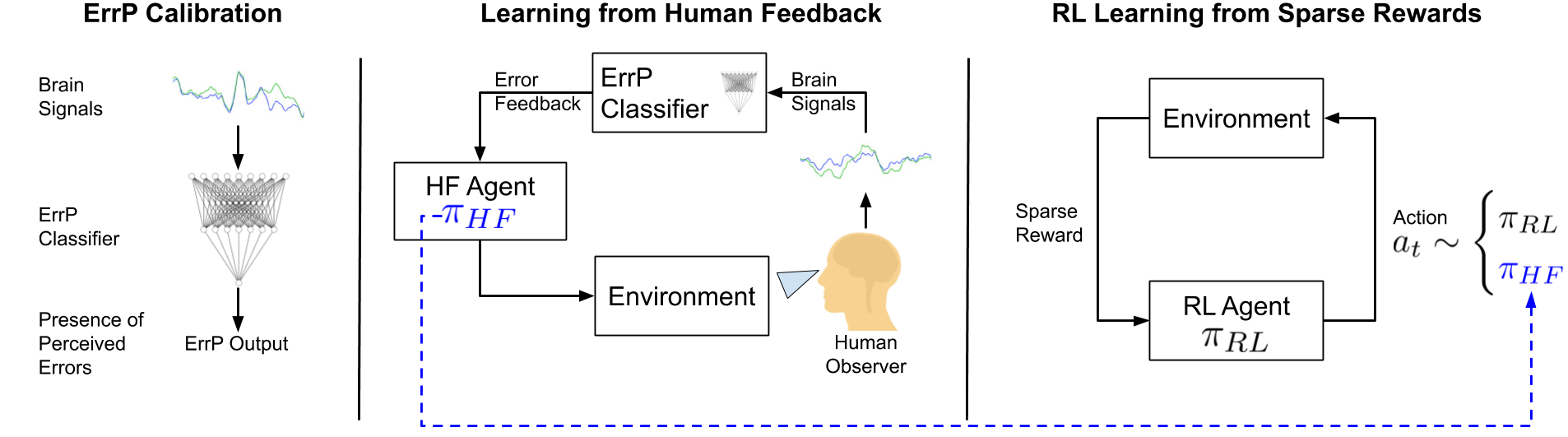
In reinforcement learning (RL), sparse rewards are a natural way to specify the task to be learned. However, most RL algorithms struggle to learn in this setting since the learning signal is mostly zeros. In contrast, humans are good at assessing and predicting the future consequences of actions and can serve as good reward/policy shapers to accelerate the robot learning process. Previous works have shown that the human brain generates an error-related signal, measurable using electroencephelography (EEG), when the human perceives the task being done erroneously. In this work, we propose a method that uses evaluative feedback obtained from human brain signals measured via scalp EEG to accelerate RL for robotic agents in sparse reward settings. As the robot learns the task, the EEG of a human observer watching the robot attempts is recorded and decoded into noisy error feedback signal. From this feedback, we obtain a policy using supervised learning that subsequently augments the behavior policy and guides exploration in the early stages of RL. This bootstraps the RL learning process to enable learning from sparse reward. Using a robotic navigation task as a test bed, we show that our method achieves a stable obstacle-avoidance policy, outperforming learning from sparse rewards only and alternative rich rewards that struggle to achieve the right obstacle avoidance behavior or fail to advance to the goal.
BCI Robot Learning
Video
Paper (ArXiv)
https://arxiv.org/abs/1910.00682
Acknowledgement
This work was supported in part by a Google Research grant and National Science Foundation grant IIS-1527747.